
This week of my Google Summer of Code project went by pretty fast, with lots of discussions and new ideas for future work with segments semantics, related to my CKEditor plugin for TMGMT. My initial goal is to extend the CKEditor with a new plugin written in Javascript, that defines segments as parts of the content and perform specific linguistic actions on them.
Achievements
My third week of work was quite busy, since I had to fix some issues, work on making the UI fully functional and add some new functionalities, as defined last week - described in my previous blog post.
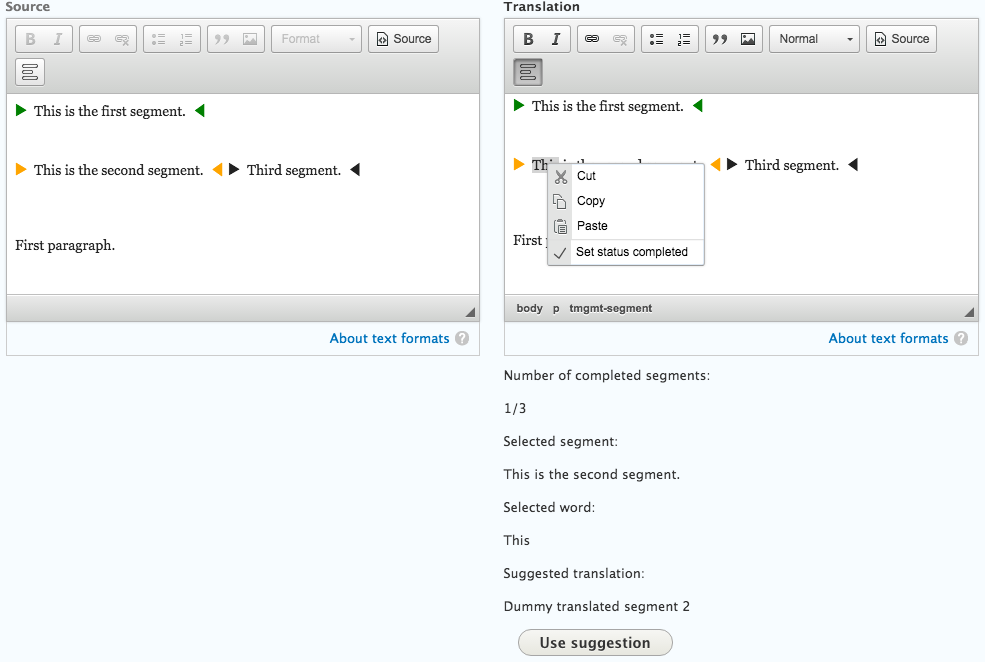
The first fix I needed to do was to populate the segments in the translation editor from the source when the ckeditor is loaded. Users actions can then be performed on this segments. All active segments are marked with colors in both editors. We could have an issue, if there are more than two editors on page - for example if the source is a node with paragraphs, it could end up in having 10 or more wysiwyg editors on page. For now, we support only one wysiwyg field. In later iterations we might add the support for more and marking segments in the corresponding ones.
Apart from fixing stuff, I also added some new functionalites this week. For now, I hardcoded a translation proposal that will end up being a returned string from translation memory. On a click of a button, the user can confirm the suggestion is right and replace the whole content of a segment with it. After that the user can right click on a segment and select the option to set the segment’s status as completed. This ends up in marking the segment in both editors in green for easier visualization. We set also a counter in the area below to display the number of completed segments.
I also worked on the area below the editor. All relevant data is displayed in a much more simple and understandable way. I will make some propositions in the future to restyle it for optimal (proper) usage, based on the UI of Google Translate and some notable CAT tools.
The image below demonstrates the current progress.
Goals for next week
As on schedule, we’re moving to the most intriguing part, connecting the frontend (my plugin) with the backend part. I will start the integration of tmgmt_memory (can be found in edurenye’s sandbox) by saving a few segments through the API and displaying the dummy translation as we are doing it now below the editor. These two functions are our starting point and will build on top of that once it’s done.
This operations could raise some extra complexity. We will have to define what happens when we will have multiple matches, for example. But this kind of questions are not in our priority list as for now.
Other than that, I will also need to fix a few smaller things, like enabling the contextual menu (right click item) only when the segments are displayed.
When all of the above is done, we will do a full code cleanup. The priority after that will be to make it really usable for users. I think one of the main blockers now is the fact that we support only two editors per page and I will focus on that part.
As the discussions with my mentor always result in a lot of new scopes and ideas. We defined new meta data for the segments to mark the quality of the translation and it’s source - if it comes from the user, machine translation or from the translation memory. We might do this by just setting the status to “needs review” and “needs work” initially. Also, another tag should be added if a segment is modified. With all this complexity of meta tags, we should define them clearly and keep good track of them. If I will find time, I might implement them this week, but the priority is connecting the translaton memory.
All my code can be viewed on my github project. Feel free to check my progress over the weeks.
